Industrial Automation Taps Information Modeling To Manage Massive Data

I took a database class in college. That course stands out in my memory for two reasons: Mary T., a tall, lanky 19-year-old brunette, and how I came to hate entities, relationships, information modeling, and everything else related to databases. Because I’ve been lucky enough to work in industrial automation all these years, and not IT, I avoided all database-related work and life was good—until now.
Entities, relationships, and information modeling (sometimes in the context of a database and sometimes not) are moving to the factory floor. It’s not something I welcomed at first, but I’ve learned to make peace with this trend. First of all, I can’t stop it. Second of all, this kind of technology can greatly enhance productivity.
This file type includes high resolution graphics and schematics when applicable.
It wasn’t long ago that we could rightly claim most devices had too little power, resources, and bandwidth to adopt the kinds of technologies used by those pencil-necked IT guys with skinny black ties and thick glasses. They did their thing on the enterprise side, building database systems for sales and order tracking, marketing, and human resources. Meanwhile, we did the real work of the company: production.
That’s over now. Our old workhorse 8-bit processors are obsolete, and every year, fewer and fewer silicon manufacturers make them. What’s more, new processors are cheaper and faster than ever, with onboard USB, Ethernet, and CAN. Processor RAM used to be measured in bytes. Now it’s measured in kilobytes and megabytes, which was unheard of just a few years ago. Likewise, I used to look at a processor to see if it had Ethernet. Now I look to see how many Ethernet media access controllers (MACs) it has, if it has an embedded Ethernet switch, and even if it has its own physical layer (PHY).
All this exponential increase in power and data year after year means there’s increasing connectivity to enterprise systems. What’s more, it’s possible to archive of all that data with fast and easy manufacturing resource planning (MRP), enterprise resource planning (ERP), and systems applications and products (SAP) connections.
So, we automation types are being dragged into the world of objects, entities, relationships, and, yes, information modeling. I admit to resisting this until I learned a little more about it. Now I marvel at the power it’s bringing to our work.
Benefits of Databases for Automation
Years ago, when I first stepped onto a factory floor, wires ran everywhere—and not just a little bit of wire, but massive amounts of wires in huge metal-basket trays. There wasn’t even a hint of serial communications, just simple 24-V inputs and 24-V outputs with a few analog connections thrown in here and there.
What do we have now? Massive amounts of data. Some automotive OEMs capture the entire weld profile of every weld they make on every car body they produce. Likewise, infant-care companies are recording hundreds of data points for every diaper they manufacture. We’re now swimming in so much data that it’s almost ludicrous, and there’s no reason to believe the data will stop proliferating.
Capturing all that data and securing it, moving it, storing it, and analyzing it is now a concern for those of us architecting manufacturing systems. But the fact is that we can’t accomplish that effectively without better mechanisms for organizing all that data. The flat-file systems that programmable logic controllers (PLCs) used in the past just aren’t adequate for today’s data explosion. That’s why it is time we adopt the technologies and practices of the people that have been immersed in data management all these years, our pencil-necked friends over in the IT department.
Exponentially growing data without a structure is unusable. But with the right structure, it can boost efficiency, productivity, quality, and cost savings. That possibility is too important to ignore.
Information Models and Data Models
Confusing matters is the existence of Information Models and Data Models. Many designers don’t really understand the difference.
For the record, an Information Model is a conceptual representation of a system devoid of any implementation details. It provides a model for designers and operators to study at the system level. On the other hand, a Data Model is a particular implementation of some or all of the components of the Information Model. It contains the specific implementation details that implementers require. In this article, we’ll only cover Information Modeling.
An Information Model is nothing more than a logical representation applied to a physical process (see the figure). It can represent something as tiny as a screw, a component of a process (such as a pump), or something as complex and large as an entire filling machine. More specifically, an Information Model is a structure that defines the component, devoid of any information on how process variables or meta-data within that structure is accessed. In fact, there are languages designed specifically for information modeling, including the Unified Modeling Language (UML).
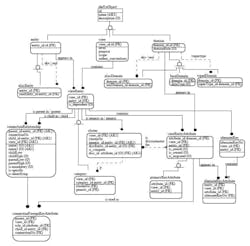
{kind=link}
The first thing you do when creating an Information Model is to decide what’s of interest and what isn’t. The Information Model for a pump might only comprise the color, case style, purchase data, and manufacturer part number if the Information Model is designed for asset tracking. Or, if the Information Model is more process-oriented, it might include none of those items, but instead offer the pump’s current RPM, operating hours, and gallons per minute. Or, a more comprehensive model could contain all of these pieces of data. Once you pick those items of interest (which are essentially entities in database lingo) and define their specific characteristics, you set up the relationships between those items.
Consider how our company’s filing machine has all kinds of devices, including valves, pumps, motors, controllers, and sensors. In the filler model, we call these Objects. Each is modeled by more specialized objects. For example, a Motor-Drive Object consists of the two components plus their subcomponents such as bearings, windings, the inverter, and so forth.
Eventually, the Information Model develops a hierarchy of Objects that reflects how the machine designers view the logical architecture of the machine. So, you might create organizational objects for entire sections of the machine such as the drive train, filling system, and labeling system. Or you could simply model the machine as a bunch of components under a Filling Machine Object.
You can get as complex or as straightforward as you’d like. The Information Model has infinite flexibility to describe your process in whatever way serves you best. Then when the Model is complete, you document your modeling process using a standard language and symbols that convey to everyone exactly what each entity is and what relationships exist between entities.
Models are Only Valuable If Someone Uses Them
But what have we really done? Your Information Model is only that: your Information Model. You may have modeled a pump with its characteristic speed and RPM. Someone else might have used a pump model that includes the current flow rate. The RPMs might be an integer value in one system and a float in another.
Since you’ve both modeled the pump differently, there is no savings in labor or productivity for either one of your customers. You may have given them a model using some open standard, but they still have to incorporate your proprietary characterizations of the Objects in the model. That’s actually not much better than what we have with current Programmable Controllers.
On top of all that, we haven’t even begun to talk about common Transports, Data Encoding, and access to the data contained in the Information Model. It’s one thing to define a nice Information Model for your device, machine, or production line. But if there isn’t any way to easily access it using that model, it really isn’t helpful to an implementer.
That problem is exactly what’s being addressed by a number of industry groups and the latest enhancement to OLE for Process Control (OPC), OPC Unified Architecture (UA).
Use Universal Models, Problem Solved
OPC UA is providing system architects with a common infrastructure for transporting, encoding, securing, and modeling data. UA is an enhancement to the popular standard, OPC, now called OPC Classic, that’s been used for data communications between industrial devices and Windows applications for many years.
The limitations of OPC Classic on Windows systems are well known. Some of its drawbacks included weak data typing, insufficient Information Modeling, limited platform support, security vulnerabilities, and inability to cross firewalls. With no support for data access over the Internet and the hesitancy of many users to deploy a lot of vulnerable Windows boxes in their production areas, OPC was clearly not the direction of the future. OPC UA solves these problems:
• UA is scalable. There are Profiles, functionality subsets, for systems as small as a single processor and as large as a mainframe.
• UA is secure. A system administrator can configure a system to be as secure or open as needed. In the most secure configurations, all messages are encrypted and both authorizations and authentications are based on standard X509 Certificates.
• UA offers multiple types of data encoding: an XML encoding for IT systems and a binary encoding for devices with fewer processor resources and less bandwidth.
• UA vastly standardizes and expands the data typing capabilities of standard OPC.
• UA supports multiple transport layers including Web Services for IT-type applications and a binary transport appropriate for small, lower resourced embedded devices.
Yet UA’s most interesting feature, at least in terms of how it supports data management, is its ability to define a standard Information Model and let mechanisms access that Information Model over different types of transport layers.
UA’s Information Model consists of UA Objects defined by Variables, Methods, and References. Here, Variables are the data values associated with the Object. Methods are callable functions that can be triggered remotely. References define the relationships between Objects and are used to implement the Object hierarchy of a system.
Providing commonality between vendors has always been a problem in the industrial-automation world. The strong Object typing in OPC UA solves that problem. Base Object types, subtypes, standard Object types, and types defined by third parties solve myriad incompatibility problems. In fact, the OPC UA type system defines all base Object types, including how each gets encoded and even how null values get encoded.
An extensible type system provides a way for software to dynamically retrieve the definition of an Object whenever it encounters Objects of unknown types. This extensibility allows vendor groups, trade groups, and others to create identifiable extensions to the typing system to standardize the support of specific problem domains.
As Complicated as Needed
The real power in the Object type system is the ability to create complex Object types. These are types that compromise an entire set of objects that can model an entire machine or a process. Using the identification system built into UA, a user can know from the Object type that a particular set of objects in one device is the exact same set of objects in another device. This type of system provides amazing productivity enhancements to system developers who, from the type of a complex Object, can identify every variable and method available for an entire system of Objects. The old days of spending hours to enter and validate Programmable Controller Tags is eliminated in this environment.
Even oil and gas companies are on board. This kind of extensible Object Typing, Data Typing, and Object Modeling is partly why the oil and gas industry and major vendors such as Emerson, Honeywell, and Invensys are standardizing on OPC UA. In fact, the MDIS Standards Group includes Distributed Control System (DCS) vendors, subsea vendors, oil and gas operating companies, and OPC UA invitees to meet the incredibly challenging demands of offshore drilling platform integration.
Offshore platforms are some of the most expensive “factories” in the world even though many of the components in these systems are no more sophisticated than the typical components you’d find in onshore industrial systems. Some of the key differences for drilling platforms include the requirement to quickly bring together massive numbers of devices from lots of vendors, preconfiguring and engineering everything before it reaches a production site, and the incredible cost of re-engineering anything once the system arrives on site.
Supportable, adaptable, standard Interfaces are critical to the implementation of these systems. The devices themselves are well understood and solidly engineered. Most system problems are in the interfacing of devices between vendors, including sometimes competing vendors. Unfortunately, interface problems are often discovered at the worst possible time—during deployment and startup in a distant and hazardous location, when the problems have the most impact on schedule and cost the most to resolve.
Finding a technology that can be as well understood and solidly engineered as the components themselves is the objective of the MCS-DCS Interface Standardization Group, also known as the MDIS Standard Group, the consultant-led international organization to standardize industrial communications on Master Control System (MCS) and DCS communications.
One of the key requirements for a technology is the ability to accurately model the characteristics of a device. All networking technologies can pass data, but few can organize information about a device into an aggregate structure—and none besides OPC UA can create types for that structure that can be documented, reused, and dynamically identified.
After an extensive analysis of competing technologies, MDIS selected OPC UA for its built-in redundancy, high-level security, and robust communications. OPC UA outperforms other technologies on the basis of these key advantages. However, when OPC UA added the ability to extend the data type and object type system to create true Information Models, it became the only real choice for the oil and gas industry.
John S. Rinaldi is president of Real Time Automation and the author of OPC UA: The Basics: An OPC UA Overview For Those Who May Not Have a Degree in Embedded Programming. A limited number of free copies is available for Machine Design readers. Request one at the Contact Us link at rtaautomation.com.
About the Author
John Rinaldi
Chief Strategist, Business Development Manager, and CEO
As Rinaldi explains it, he escaped from Marquette University with a degree (cum laude) in Electrical Engineering to work in various jobs in the automation industry before once again fleeing back into the comfortable halls of academia. At the University of Connecticut he once again talked his way into a degree, this time in Computer Science (MS CS). He achieved marginal success as a control engineer, a software developer, and an IT manager before founding Real Time Automation, "because long-term employment prospects are somewhat bleak for loose cannons," he says.
With a strong desire to avoid work, responsibility, and decision making (again, as he explains it) Rinaldi had to build a great team at Real Time Automation. And he did. RTA now supplies network converters for industrial and building automation applications all over the world. With a focus on simplicity, U.S. support, fast service, expert consulting and tailoring for specific customer applications, RTA has become a leading supplier of gateways worldwide. Rinaldi admits that the success of RTA is solely attributed to the incredible staff that like working for an odd, quirky company with a single focus: Create solutions so simple to use, the hardest part of their integration is opening the box.
Rinaldi is a recognized expert in industrial networks and the author of three books: The Industrial Ethernet Book, OPC UA: The Basics (an overview of the enhancements to OPC technology that allow for Enterprise communication), and a book on women and relationships — as he puts it, proof that insight into a subject is not necessarily a prerequisite for writing about it.
Voice Your Opinion!
To join the conversation, and become an exclusive member of Machine Design, create an account today!

Leaders relevant to this article: